


- switch(OpCodeGruppe(bytes))
- {
- case OGL:
- break;
- case WGL:
- break;
- case XGL:
- break;
- case WRITE:
- switch(WriteOpCode(bytes))
- {
- case Bytes1:
- break;
- case Bytes2:
- break;
- case Bytes4:
- break;
- case Bytse8:
- switch(Write8OpCode(bytes))
- {
- case Register0:
- break;
- case Register1:
- ...
- }
- break;
- }
- break;
- case READ:
- break;
- default:
- }
|
Aktuelle Zeit: Sa Aug 01, 2026 20:18 Foren-Übersicht » Programmierung » OpenGL |
Unbeantwortete Themen | Aktive Themen |
Data driven rendering
Moderator: DGL-Team
|
|
Seite 1 von 2 |
[ 16 Beiträge ] | Gehe zu Seite 1, 2 Nächste |
|
| Autor | Nachricht | |||||
|---|---|---|---|---|---|---|
| TAK2004 |
|
|||||
Registriert: Di Mai 18, 2004 16:45 Beiträge: 2623 Wohnort: Berlin Programmiersprache: Go, C/C++ |
|
|||||
| Nach oben | ||||||
| Lord Horazont |
|
|||||
Registriert: Do Sep 02, 2004 19:42 Beiträge: 4158 Programmiersprache: FreePascal, C++ |
|
|||||
| Nach oben | ||||||
| Lord Horazont |
|
|||||
Registriert: Do Sep 02, 2004 19:42 Beiträge: 4158 Programmiersprache: FreePascal, C++ |
|
|||||
| Nach oben | ||||||
| yunharla |
|
|||||
Registriert: Mo Nov 08, 2010 18:41 Beiträge: 769 Programmiersprache: Gestern |
|
|||||
| Nach oben | ||||||
| TAK2004 |
|
|||||
Registriert: Di Mai 18, 2004 16:45 Beiträge: 2623 Wohnort: Berlin Programmiersprache: Go, C/C++ |
|
|||||
| Nach oben | ||||||
| TAK2004 |
|
|||||
Registriert: Di Mai 18, 2004 16:45 Beiträge: 2623 Wohnort: Berlin Programmiersprache: Go, C/C++ |
|
|||||
| Nach oben | ||||||
| TAK2004 |
|
|||||
Registriert: Di Mai 18, 2004 16:45 Beiträge: 2623 Wohnort: Berlin Programmiersprache: Go, C/C++ |
|
|||||
| Nach oben | ||||||
| TAK2004 |
|
|||||
Registriert: Di Mai 18, 2004 16:45 Beiträge: 2623 Wohnort: Berlin Programmiersprache: Go, C/C++ |
|
|||||
| Nach oben | ||||||
| Vinz |
|
||||
Registriert: Fr Mai 11, 2012 13:25 Beiträge: 229 Programmiersprache: c++, c, JavaScript |
|
||||
| Nach oben | |||||
| yunharla |
|
|||||
Registriert: Mo Nov 08, 2010 18:41 Beiträge: 769 Programmiersprache: Gestern |
|
|||||
| Nach oben | ||||||
| TAK2004 |
|
|||||
Registriert: Di Mai 18, 2004 16:45 Beiträge: 2623 Wohnort: Berlin Programmiersprache: Go, C/C++ |
|
|||||
| Nach oben | ||||||
| TAK2004 |
|
|||||
Registriert: Di Mai 18, 2004 16:45 Beiträge: 2623 Wohnort: Berlin Programmiersprache: Go, C/C++ |
|
|||||
| Nach oben | ||||||
| TAK2004 |
|
|||||
Registriert: Di Mai 18, 2004 16:45 Beiträge: 2623 Wohnort: Berlin Programmiersprache: Go, C/C++ |
|
|||||
| Nach oben | ||||||
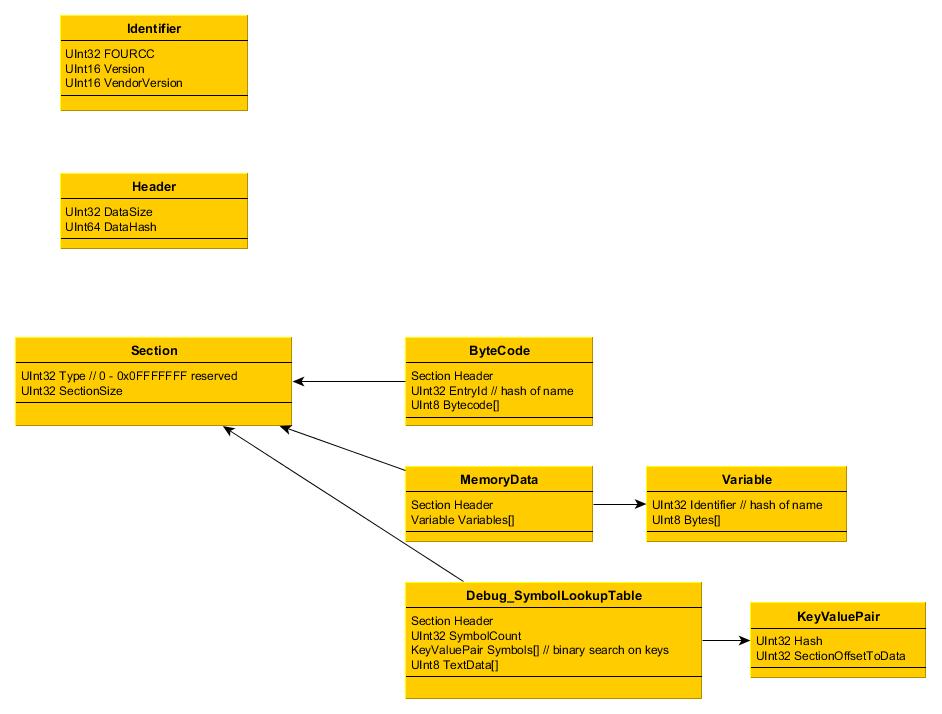
| yunharla |
|
|||||
Registriert: Mo Nov 08, 2010 18:41 Beiträge: 769 Programmiersprache: Gestern |
|
|||||
| Nach oben | ||||||
| TAK2004 |
|
|||||
Registriert: Di Mai 18, 2004 16:45 Beiträge: 2623 Wohnort: Berlin Programmiersprache: Go, C/C++ |
|
|||||
| Nach oben | ||||||
|
|
Seite 1 von 2 |
[ 16 Beiträge ] | Gehe zu Seite 1, 2 Nächste |
Wer ist online? |
Mitglieder in diesem Forum: 0 Mitglieder und 12 Gäste |
| Du darfst keine neuen Themen in diesem Forum erstellen. Du darfst keine Antworten zu Themen in diesem Forum erstellen. Du darfst deine Beiträge in diesem Forum nicht ändern. Du darfst deine Beiträge in diesem Forum nicht löschen. Du darfst keine Dateianhänge in diesem Forum erstellen. |